Part 1 - The Issue
Hey everyone!
While @Hunter5683 keeps pumping out new devlogs regularly, it’s been quite some time since you’ve heard about any behind-the-scenes happenings.
Engine
As you might already know, a few months ago we made a critical decision and switched engines from Unity to Unreal Engine. I don’t want to delve into the details why, as we’ve covered this in past updates, but key elements were stability and ease of use of the engine. While I love Unity for being very clean and lightweight, you have to develop most of the tools yourself or use third-party assets, which are often not entirely compatible with your project.

Backend
Another issue was our backend technology stack. Respark uses our custom API server called Sentinel for authentication and communication between game servers and the persistent database, which in our case is a MongoDB cluster. If you have created an account and logged into this forum via https://user.playrespark.com/, you have used Sentinel to authenticate. Sentinel is written in Node.js by @Spitap and me. Even though there have been a few incidents related to expired SSL certificates, Sentinel has been running without any issues for months at a time without needing a restart due to memory leaks or other problems.
Game Server
Another part of the backend infrastructure is the game servers themselves. You connect to them via your game client and play, while they handle network synchronization between you and other players, simulate the game world, and more.
For the whole lifetime of the project’s Unity repository, we’ve used the Mirror networking solution, which initially felt like a godsend. It was integrated into Respark’s game repository and utilized Unity for physics and other systems related to the game, while adding a layer of reliable and fast networking. @Spitap then found a way to not only build and deploy the game server automatically using our GitLab CI/CD pipeline, but also strip all assets like textures, images, meshes, and audio from the server build, ultimately reducing its size and increasing performance. This meant that we just added new code, pushed changes into Git, and within minutes an updated server instance was running.
This all seemed great, so what’s the deal? As the game server ran on the Unity engine, its functionality became a huge bottleneck. Unity (and most other engines) runs the game simulation primarily on the main thread. This is somewhat okay for the game client, as players usually use CPUs with high clock speeds and fewer cores, but server CPUs are different—they have lower clock speeds but many more cores. For the game server to be efficient, it needs to utilize the full potential of the hardware it runs on.
After many benchmarks and actual playtests with founders, the performance wasn’t terrible, but we knew we couldn’t increase player and NPC counts too much because most of the action was simulated on a single CPU core. By the way, the heaviest system on the server was actually AI pathfinding and behavior simulation, which I will get back to later. There are, of course, ways to go around this by using tasks, threads, Unity’s ECS and job systems, etc., but having both server and client code started to become a huge mess.
When we decided to switch to Unreal, we inherently lost the game server solution as well, so we faced another decision: should we use built-in Unreal networking or write our own? It didn’t take long to see benchmarks, case studies, and forum posts to find out that UE’s networking is definitely not suitable for a large-scale open world MMO where you want everyone running on a single server instance. If we were to build our server technology on top of Unreal like we did with Unity, we would have to use C++, which would result in very unstable code because of how rapidly we need to add new features, with little to no time for debugging (so that we can finally show you something in a picture or a video).
So yeah, this was not an option either, but there was only one option left—to create our own custom game server technology from scratch. This sounds very scary, but after many months of work, many trials, errors, refactors, and rewrites, we finally have a somewhat “usable” solution which we can build upon, but there is still much more work ahead.
Congratulations, you’ve just finished the prologue of this post, because now I’m going to present the real deal (if this forum will even let me post something so long).
Part 2 - The Solution
Let's go!
So the work started again. The game design team kept writing down ideas with @Hunter5683 in the lead, the art team kept creating new assets with @Storoj in the lead, and thanks to Unreal’s awesome blueprint system, non-programming members of the team could develop game mechanics on their own, increasing the speed of development. We are also glad to have a new addition to the dev team @rasharn0121, who’s been working on a lot of client-side gameplay, most notably the new refactored gliding system! While everyone had great results and could visualize them, I was working behind the scenes on the new server technology. To be fair, it was more of an experimental phase, with dozens of repos created and deleted, trying out different approaches and strategies. Finally, after all these painful days and nights, our custom server technology is starting to take shape. I want to present to you how it’s supposed to work for anyone who would be insane enough to start developing an open world action shooter MMO game as a hobby project.
Respark's Game Server
As I’ve stated before, it was crucial for the game server to handle hundreds of players and thousands of NPCs running around a single server instance. (We have yet to do proper benchmarks to find out if we did a good job.) By server instance, I mean a single game server application running on server hardware dedicated only to this purpose.
The first step was to determine the programming language to use, and with so much praise from developers over the past few years and a few experiments, Rust was the best choice, though it is not yet much explored in this space. With its memory safety, lack of garbage collector, strict types, awesome crate system for libraries, and many other features, it was the best decision in my opinion.
The server application can be split into multiple modules:
Networking
We need to use both UDP and TCP protocols for synchronizing different parts of the game and also handle clients asynchronously, which is the right job for Rust’s Tokio runtime.
Serialization & Compression
To send and receive data between our server and Unreal Engine, we had to come up with a solution for serialization that both sides can use to deserialize data into 1:1 equivalents. That’s where Flatbuffers come in. We simply define the schema of our network messages and let the Flatbuffer compiler generate serialization code in a specified language for us. To lower the size of data transferred over the network, we are using LZ4 compression, which is not very efficient but is very fast—we might iterate over different solutions later.
Game Simulation
This is where the work is currently focused. To simulate the game world efficiently across all CPU cores, we have decided to use ECS (Entity Component System) and are currently experimenting with simulating systems concurrently with a load balancer on multiple CPU cores.
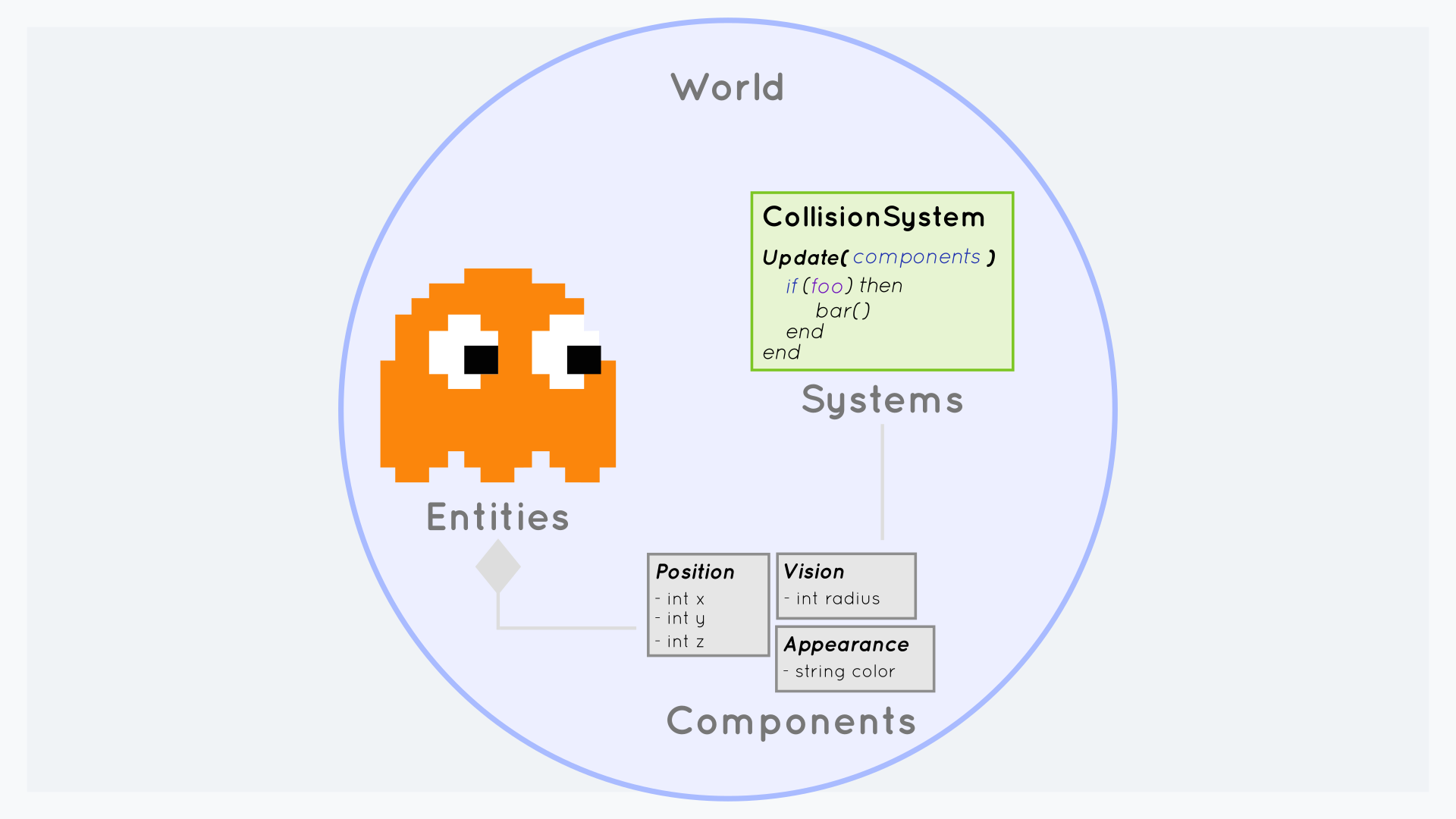
Spatial Hashing & Interest Management
For example, if you are doing your own thing in the game and another player 2 kilometers away starts jumping, you don’t really need to know. To avoid the server sending you this information, we need to use an interest management system, which decides if you should receive the data or not. Because this system would have to iterate through all players multiple times per second and calculate distances between them, it’s not very efficient. That’s where spatial hashing comes in.

It allows us to split the world into chunks and only synchronize entities that are in your or neighboring chunks, greatly reducing the bandwidth and processing intensity on your PC while playing the game.
Spatial hashing is also used for gameplay-related queries. For example, if you place down a turret and it only shoots enemies within a 20-meter radius, you have to keep checking distances to all enemies and trigger the turret if one of them is less than 20 meters away. This would mean that again the turret would have to iterate over all NPCs on the server, which is very inefficient. By querying the spatial hashing system and receiving only relevant entities, we can increase the speed of this process.
Persistent Database
Players will most probably connect to a different server instance every time they join the game. For this reason, it’s not possible to save their progress on the game server itself; it has to be stored in a central database persistently. That’s where Sentinel comes in again. Game servers use Sentinel to regularly save and retrieve player data from the MongoDB database cluster.
Asynchronous & Parallel Processing
We want the server to run smoothly and not contain any roadblocks that would slow any of its functionality down. That’s why most of the logic is processed in different Tokio tasks, which are assigned to different threads. In order for them to communicate with each other, they use MPSC (multi-producer, single-consumer) channels as message queues and process them asynchronously when they have time.
Pathfinding
As stated before, the game world, including AI NPC behavior, is processed by the ECS model. However, we had to solve one of the biggest issues from the Unity repository, which was pathfinding. NPCs usually have to change their path multiple times per second because the player moves and they need to react to it. Because of this requirement, the pathfinding system needs to be extremely fast. While there were some open-source libraries for pathfinding already, we decided to create our custom solution and made it open-source for anyone to use in their projects. It’s currently in the development phase, but it already works and has great results.
RePath - Open Source Pathfinding Library For Rust
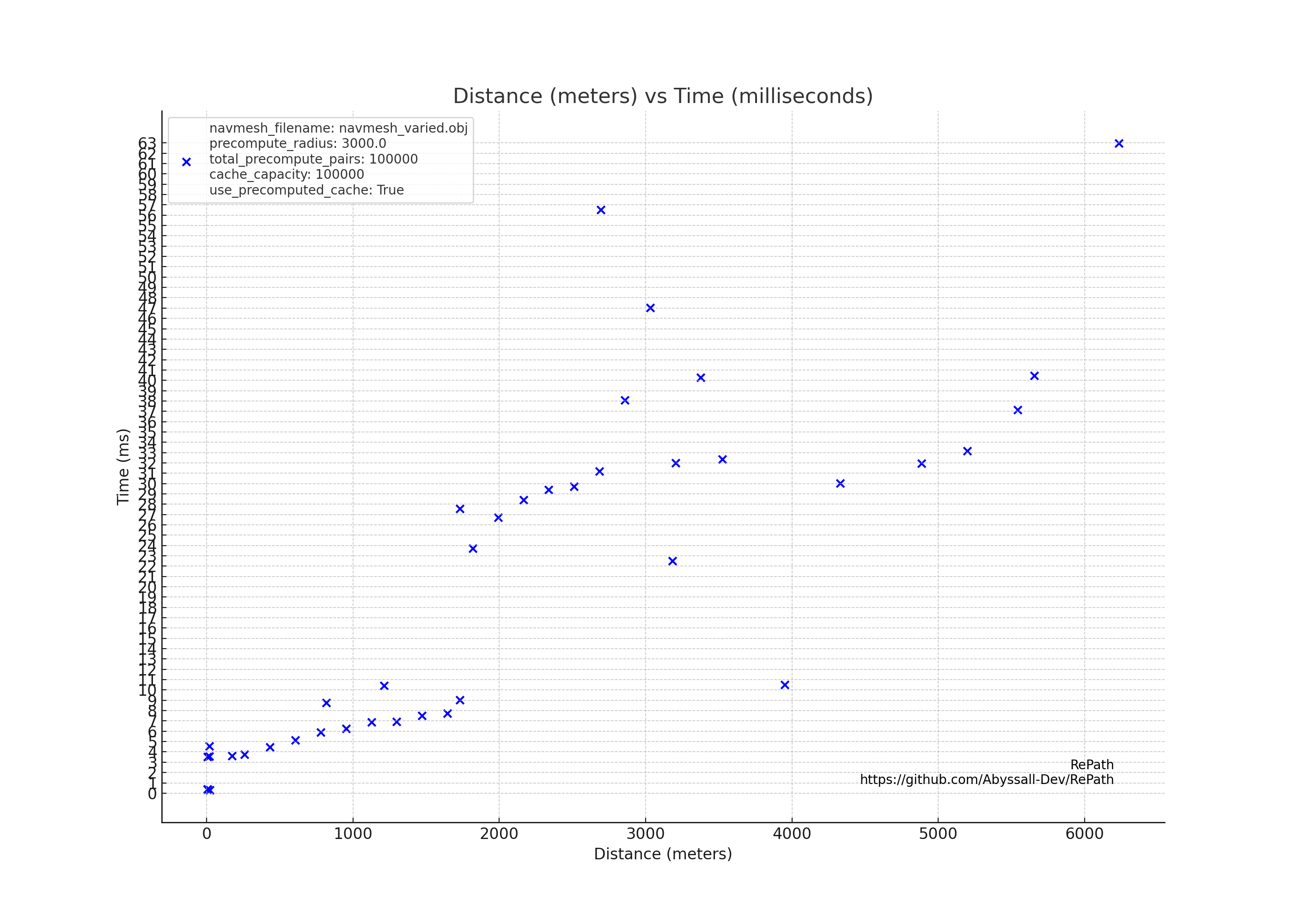
It uses a cache to store frequent paths. If the path the NPC wants to generate already exists in the cache, the retrieval can happen in under a microsecond. For longer paths, it takes much more time, but even a few milliseconds for a kilometer-long path is a great achievement.
Read more in the GitHub repository. We would be happy if anyone contributed to the project or used it in their own projects. ![]()
There will be more open-source projects coming out of our studio very soon because just as we are taking, we also need to give back to other developers.
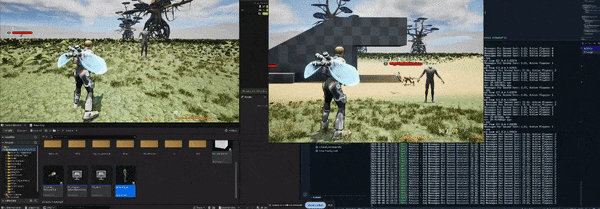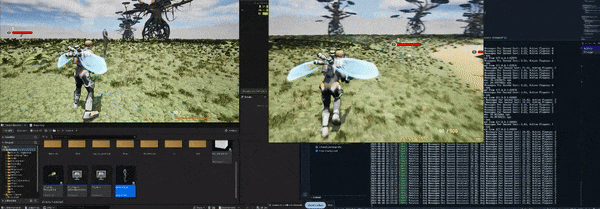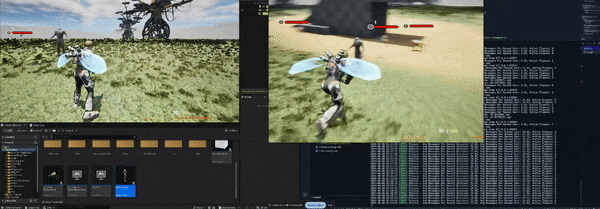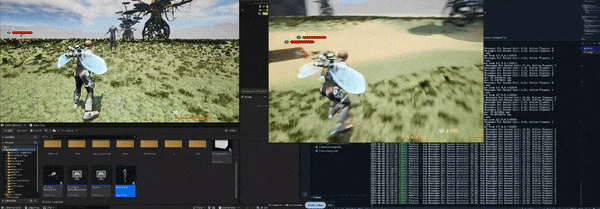
Here is a small showcase of the movement network synchronization utilizing our custom written server solution with no character animations being synchronized yet.